Exploring Rap & Country Music Lyrics¶
Background¶
For the fourth project ("Project Fletcher") of Metis' Data Science bootcamp, which tasked us with using NLP and unsupervised learning, I chose to explore the language-space of two musical genres that seem diametrically opposed: Rap and Country. Can we identify features that distinguish or define them? Also, given the seemingly unbreachable cultural chasm between the audiences of these genres, any similarities we find between them could serve as a common ground.
Tools¶
- Webscraping: API, BeautifulSoup
- Data Handling: MongoDB
- Text Processing: nltk, gensim, sklearn
- Modeling / Analysis: nltk, sklearn, numpy
- Data Visualization: Flask, d3.js
Data & Methods¶
I leveraged Billboard.com’s weekly listing of top 20 songs to guide which songs to scrape lyrics for. Genius.com has an API and is a reknown source for rap lyrics, so it served as my lyrics source. I obtained lyrics for over 2700 songs dating back to 2008. While not a particularly large dataset, it was sufficient for a proof of concept approach.
I performed basic text cleaning, removing punctuation and nltk’s built-in English and Spanish stop-words. I also added additional song-related stop-words such as “yeah” and “oo”. I removed any words between brackets, as lyrics commonly contain bracketed words to denote different parts of songs (e.g. [Chorus]) or featured artists (e.g. [Pitbull]). (See Footnote 1.)
I split the songs into 1- and 2-word "tokens" and calculated the frequency of these terms in my corpus. (See Footnote 2.) From these term frequencies, I constructed a 'document-term-matrix' (DTM): each row is a song, and each column represents a word token. My DTM contained nearly 45,000 features or columns. With only 2700 songs, most values in this matrix will be null. A sparse matrix such as this is nearly ubiquitous in natural language processing (NLP).
Topic Modeling with LDA¶
In NLP, Topic Modeling is a statistical method for discovering the collection of topics a corpus of documents contains. Latent Dirichlet Allocation (LDA) is one such topic modeling approach in common use today. In LDA, documents are generated from mixtures of topics, which themselves have distributions of word probabilities. The topic distributions within a document have sparse Dirichlet prior distributions, which result in the documents covering a small set of topics, and topics containing a small set of words; this aligns with intuition.
pyLDAvis is a handy library that enables interactive visualization of topic modeling. Here are the results from my 9-topic modeling of the Rap & Country music song corpus:
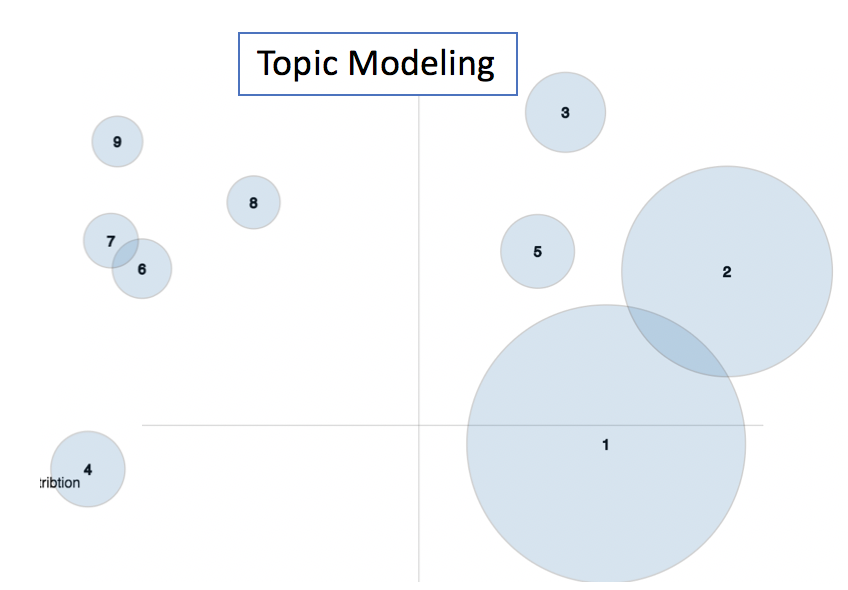
Results¶
We can see that there are two "main" topics. Examining the most common words in each of these topics, we see that one topic appears to be "Country" and the other "Rap". (Note that the Rap topic contains several offensive words, which have been edited for propriety.)

Given that we appear to have a 'Country' topic and a 'Rap' topic, we would expect Country songs to have a high proportion of Topic 1 and Rap songs to have a high percentage of Topic 2. This is more or less what we observe:
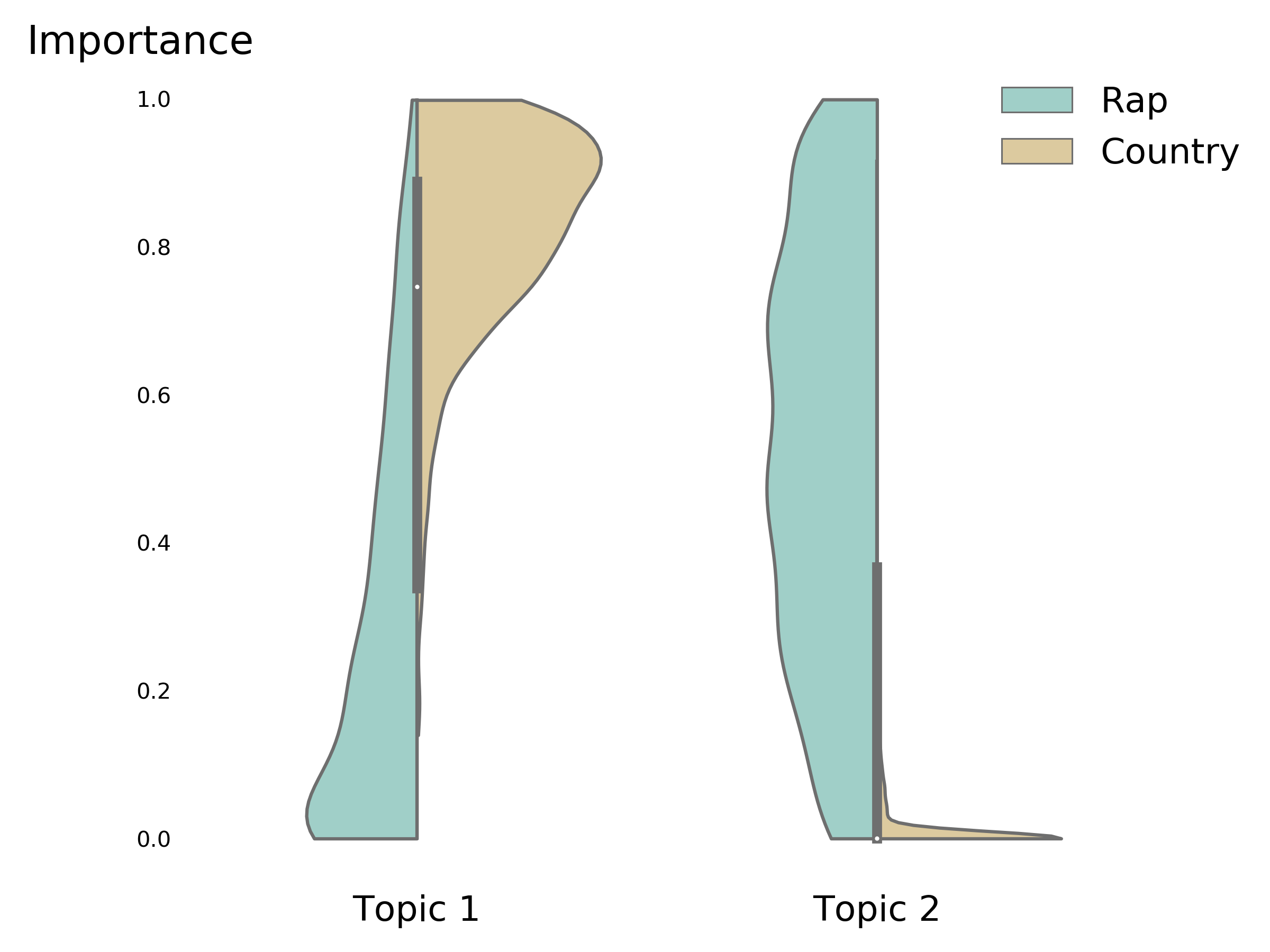
The above is a split violin plot. The distribution of topic importance is plotted along the vertical axis. The left half of a plot corresponds to the distribution for the Rap genre; the right half for Country. We can see that Country songs indeed are characterized by high Topic 1 importance. Rap songs actually have a broad distribution of Topic 2 importances, but nearly no Country songs feature this topic.
Gangsta Score¶
Building on the observation that the relative importance of these two topics in a song appears to discriminate between the two genres, I engineered a feature I call the “Gangsta Score":
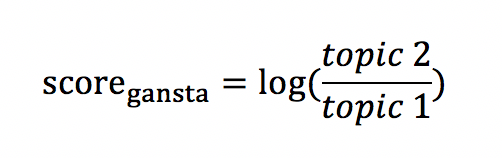
Thus, a song high in Topic 2 (the “Rap” topic) will have a positive score. If we examine the distribution of scores by genre, we observe that rap songs tend to fall on the positive end of the Gangsta Score scale, while country songs fall on the negative end, as expected:
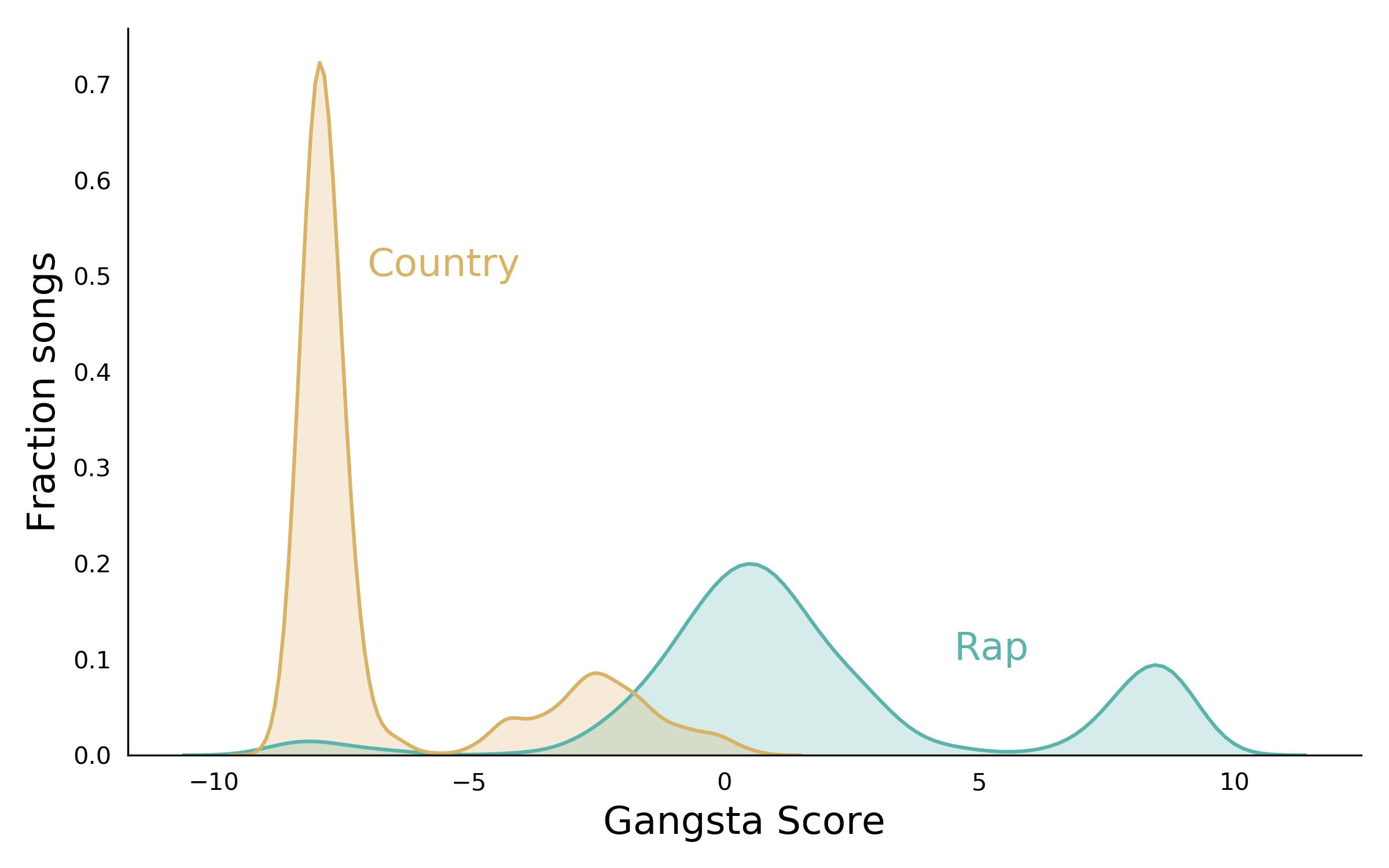
However, each genre is multimodal, so there is clearly something more complex going on. There is also significant overlap between the two genres in the area between -3 and 0 on the Gangsta Score scale. I decided to investigate this further...
As a result of assigning each song a distribution of topic importances, LDA effectively reduces the dimensionality of our sparse matrix from 2700 x 45,000 to 2700 x 9. This enables us determine similarity between songs by computing the distance between song vectors and subsequently to cluster songs according to their similarity. I used K-Means clustering with cosine distance. Surprisingly, over 30% of rap songs were clustered with Country songs:
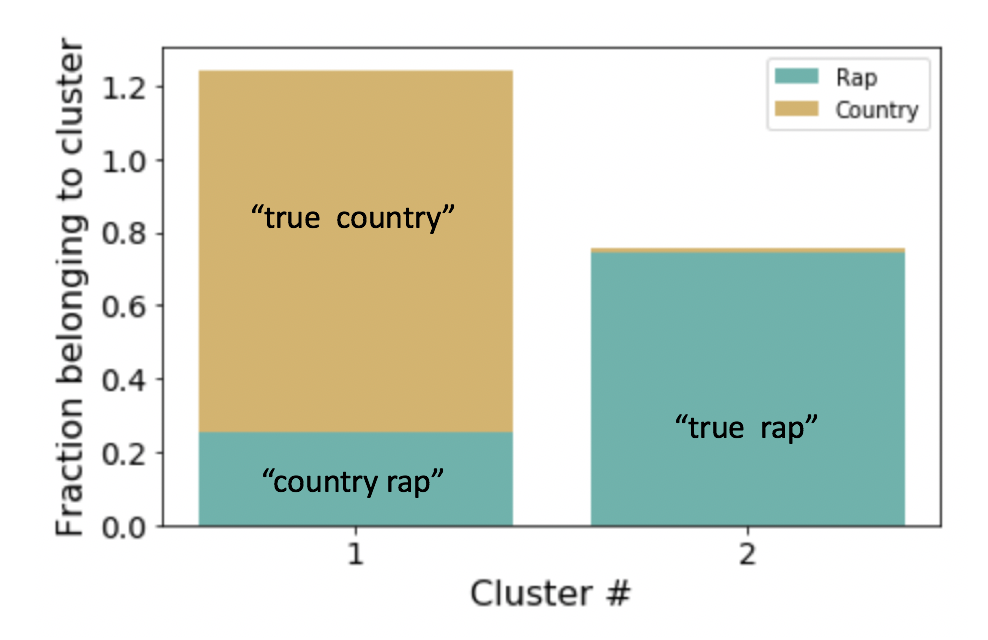
If we pull out Rap songs that are clustered with country songs, and re-plot the score distributions, we find that these “country-rap” songs fall in the area of overlap:
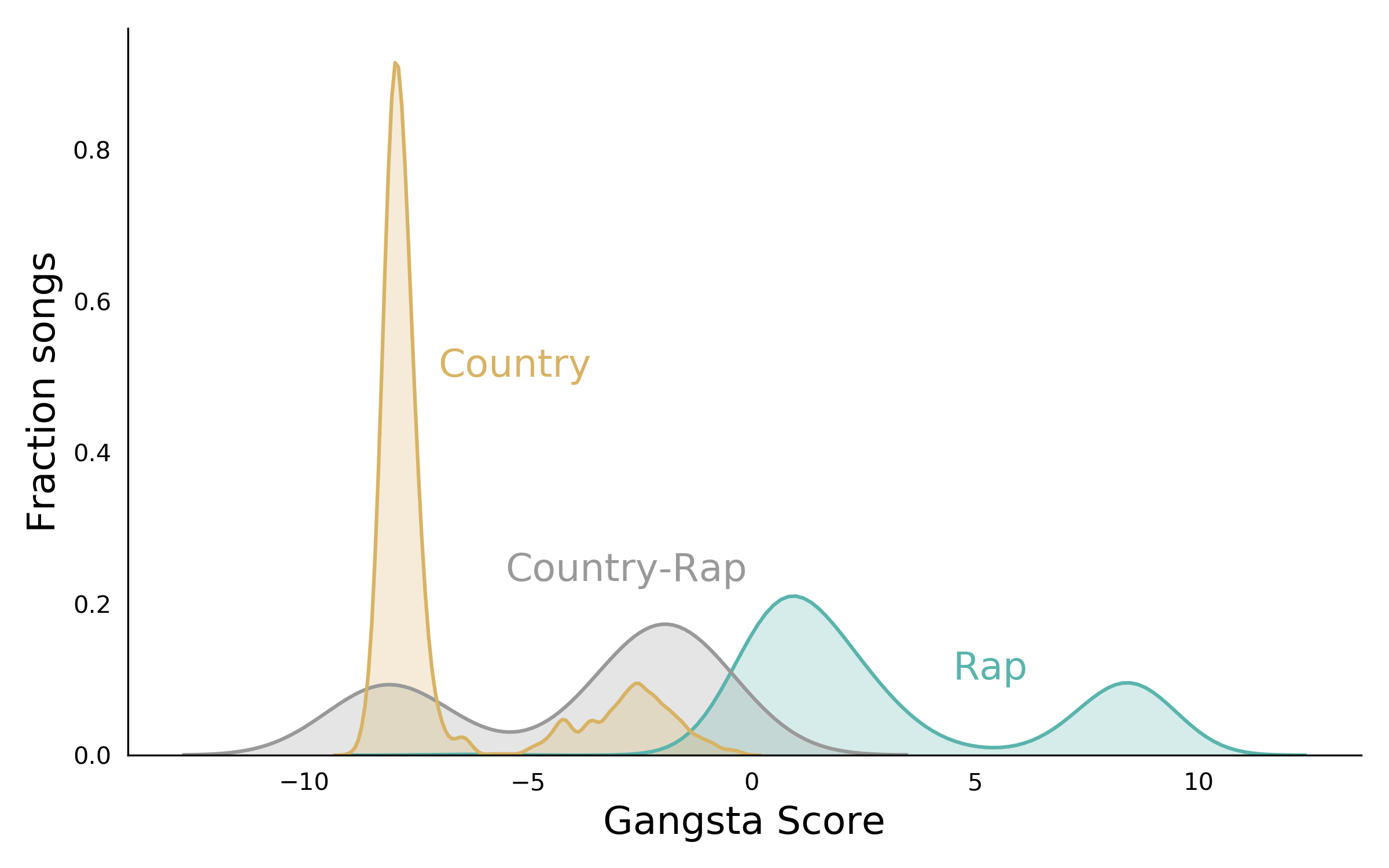
Examination of lyrics in various portions of the Gangsta Score scale support its utility. Rap songs at the high, positive end feature more offensive language; “country” rap songs in the area of overlap have more innocuous lyrics; Country songs close to 0 are more vulgar than those whose score is more negative. Click here for examples. (Note some lyrics are offensive in language or content.)
I created a Web App that allows aspiring artists to enter their lyrics and receive a 'Gangsta Score'. This would enable them to tailor their lyrics to a "Rap", "Country" or cross-over audience.
Footnotes¶
- This had the unintended side effect of removing "aside" or "echo" lyrics that occur at the end of a phrase. These were often a repetition of the preceding phrase and were far more common in rap lyrics.
- I found stemming and lemmitizing to give poorer results in terms of topic interpretability, as did term-frequency inverse document frequency (TF-IDF).
You can find the code for this project here.